
中国半导体照明网:本文提出了一种具有分布式布拉格反射器 (DBR) 结构的 Micro-LED 背光模块,以实现出色的 Micro-LED 背光模块性质,并使用深度强化学习 (DRL) 架构进行光学设计。在DRL架构中,针对微观和宏观两种极端结构的计算环境问题,本篇提出了环境控制代理和虚拟现实工作流程来保证设计环境参数与实验结果高度相关。本文通过上述方法成功设计了具有DBR结构的Micro-LED背光模块。采用DBR结构的Micro-LED背光模块相比没有DBR的Micro-LED背光模块,均匀度性能提升32%,DRL方法所需的设计计算时间仅为传统光学仿真的17.9%。
随着近几十年半导体制程技术的发展,具有优良直接能隙特性的三五族化合物半导体已广泛应用于大功率电子、照明、显示技术等各个领域。发光二极管 (LED) 在显示技术中应用最为广泛。以LED为显示光源的背光显示技术带来了优于传统显示解决方案的能源应用效率和更好的色彩质量,并引导整个显示产业到更薄的设计。
近十年来,2010年推出的LED背光显示技术已在全球市场得到广泛认可。未来有一个更精确的蓝图:更高的能源应用效率,更高的色彩饱和度,以及具有超高对比度度控制能力的Micro-LED背光模块。Micro-LED背光模块在为前瞻显示带来诸多优势的同时,也带来了许多新颖的挑战和创新机会。 例如,通过在NCTU SCLAB研究奈米球光罩蚀刻技术,可以减轻在制程阶段由薄外延设计产生的量子局限史塔克效应(QCSE)。由于芯片尺寸比,照明角度设计区域受到限制,提出了新的低光损耗光学设计挑战。相当多的研究成果也测量了整体背光设计的间接物理参数。设计具有高均匀性和低功耗的Micro-LED模块在今天仍然是一项重大挑战。
此外,由于量子点材料可以显著提升显示器的色彩质量,量子点色彩转换技术也是前瞻性显示技术中一项极为重要且被广泛讨论的技术。在过去的半个世纪中,许多成熟的光学设计方法和物理概念已经建立并用于各种研究工作。在LED领域,对不同尺度的物理模型进行了大量的研究和分析。但是,由于宏观尺度和微观尺度的具体表现分别是粒子和波,在进行光学设计时,往往不可能同时进行宏观尺度和微观尺度的设计。由于晶粒结构的微观尺度和背光模块的宏观尺度都存在于Micro-LED模块中,这种现象已成为追求超薄设计的Micro-LED模块的一个挑战。
本文构建了一套光学编程程序,并介绍了一种环境控制代理技术来控制宏观和微观尺度。此外,由于传统的优化计算方法,如差分进化算法和基因算法,都是rule-based的算法,具有可解释性和使用较少超参数的特点。这种方式虽然方便开发者使用,但对于可变性较大的主题,应用起来难度更大。
相反,由大量数据驱动的数据驱动算法有很多超参数来解决各种变化的问题。为了实现高度适应性的解决方案,避免过度敏感的搜索过程导致无法找到全局最大值或最小值,本研究提供人工智能深度强化学习技术,并采用Google DeepMind的double DQN(DDQN)架构作为核心网络创建人工智能光学设计代理以实现最佳光学设计。深度强化学习 (DRL) 和环境控制代理技术在本研究中得到充分实现。此外,基于人工智能模型的推理结果,成功生产出超薄、高效、高均匀度的Micro-LED模块。
实验与算法设计
1.Micro-LED 模块及光学介绍
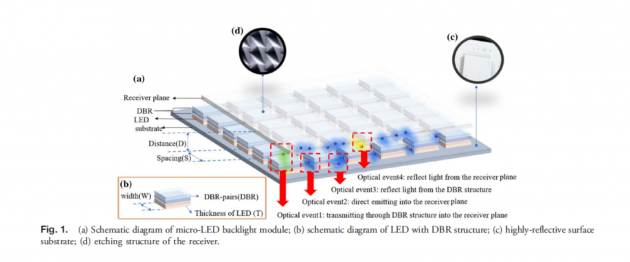
在前瞻显示应用中,Micro-LED背光模块是当前的主流发展技术,一个完整的Micro-LED背光模块如图1所示。主要结构包括基板、接收平面;LED数组,其波长光谱呈高斯分布,光谱峰值为445nm,光谱宽度为18nm;以及LED的结构设计。
在本文中,选择分布式布拉格反射器(DBR)结构作为控制LED发光角度的结构,如图1(b)所示,覆盖LED数组下方的每个LED。在这种模块结构中,当光从LED发射到接收器平面时,有四种主要类型的光学事件。
(1) 通过DBR结构发射到接收平面:LED发出的光入射到DBR结构的角度没有达到全内反射角。因此,它遵循Snell's Law并通过折射进入接收器平面。
(2)直接射入接收平面:LED产生的光直接射入接收平面,不经过任何物体。
(3)从DBR结构反射光线:当光入射到DBR的角度达到全内反射角(TIR)并进入接收平面时,产生反射光。
(4)从接收平面反射光线:当光线进入接收平面时会产生反射光。
由于上述四个光学事件,光会在接收器平面、DBR和基板之间产生许多反射事件。如果反射没有入射到完全反射的表面上,则会导致光学系统中的能量损失。
为了降低损耗,在模块设计中,如图1(c)所示,在基板表面使用高反射率涂层进行涂层,并使用蚀刻图案的扩散板作为接收平面,如图1(d)所示。为了减少能量损失,基板上涂有厚的 TiO2 层。在完成模块的框架设计后,在设计Micro-LED背光模块时应考虑的重要变量如图1(a)和图1(b)所示。
(1)距离(D):基板与接收器平面之间的距离
(2)间距(S):LED芯片之间的间距
(3)宽度(W):LED的宽度
(4) DBR对数(DBR):DBR对数数量
本研究将为架构的四个变量设计开发一种优化方法。
2.整体设计工作流程
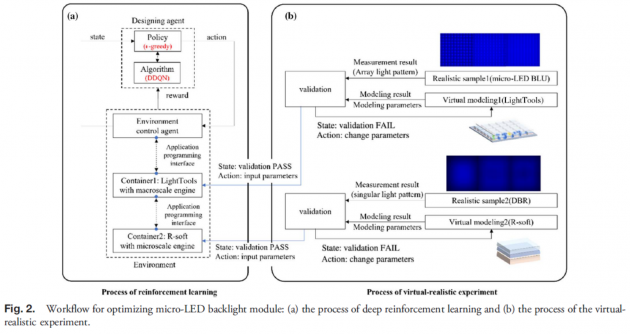
如图2所示,我们提供了一套全面的设计方法,以实现完美的模拟和优化结果,这个设计过程分为两个主要模块,一种是深度强化学习的优化引擎。该模块的任务是在受控环境中优化人工智能代理的设计,另一个核心模块是模拟验证,如图2(b)。此验证旨在确保设计模型的环境与实际现场一致。因此,差距小到足以在模拟设计和实现之间具有足够程度的可靠性。
图 2(a) 显示了两个核心模块组成了优化引擎,即设计代理和环境。设计代理每次向环境发出指定动作执行后,环境将环境状态和奖励报告给设计代理。设计代理中的算法网络学习深度神经网络(DNN)并引导策略函数给出动作。当奖励饱和时,经过多次迭代,可以获得光学设计优化。本文使用的神经网络模型是Google 2015年发布的double deep Q-learning(DDQN)网络模型,以ε-greedy为优化任务的核心。另一个对设计结果有重大影响的部分是强化学习架构中的环境。由于Micro-LED背光模块既有奈米级结构也有毫米级模块结构,因此必须兼顾宏观和微观的操作。一般来说,波动光学在微观尺度的计算中占主导地位;本文使用 Synopsys的R-soft软件进行计算。另一方面,宏观尺度计算一般采用几何光学进行光学计算;本文采用Synopsys的LightTools软件进行计算。虽然有精密的计算器辅助工程(CAE)工具可以分别处理微观和宏观问题,但Micro-LED背光模块必须同时处理两个极端维度,因此我们添加了环境控制代理的概念和容器进入环境,如图 2(a) 中的环境所示。我们在环境设计中分别设置LightTools和R-soft运行所需的环境和数据库,然后利用环境代理程序对两个容器任务进行协同调度。通过环境控制代理和独立容器设置,可以有效解决超大规模计算问题。在完成基于环境控制代理和容器的环境架构后,如图2(b)所示,为完成高可靠性模拟,我们在虚拟环境和实际场景之间进行两组极端环境单项参数验证,我们称之为虚拟现实实验。在虚拟现实实验中,我们将完成的Micro-LED 数组样本图像与 LightTools 仿真图像进行比较,并通过验证量化差异以获得最佳的现实参数组合。同样,我们也使用完成的具有 DBR 结构的Micro-LED与 R-soft的仿真结果图像进行比较,并通过验证量化差异,以获得最佳的现实参数组合。本文将使用图2(a)的优化架构和图2(b)的沉浸式环境设置来设计高可靠性的micro-LED背光模块。
3.建立环境控制代理
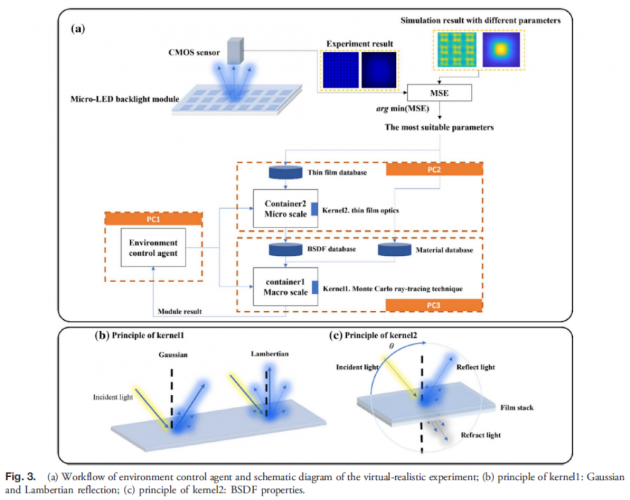
建立环境的工作流程如图3(a)所示。首先,我们实现了第一批Micro-LED背光模块原型,使用CMOS传感器捕获图像,并使用单芯片和芯片数组图像作为优化仿真参数的基准。另一方面,DBR和Micro-LED背光模块的光学仿真模型分别使用R-soft和LightTools建立。有六组实验组合:
(1) 背光模块中没有DBR的单个氮化镓
(2) 背光模块中带有2.5对DBR的单个氮化镓
(3) 背光模块中带有5.5对DBR的单个氮化镓
(4) 背光模块中没有 DBR 的氮化镓数组
在仿真中,背光模块的底部反射率和接收器反射率是必不可少的系统变量。为了建立接近准确的环境参数,实际样品的光学反射特性通常具有散射特性。反射光的散射方式大致分为Gaussian type(反射光的主方向与法线的夹角与入射角一致)和Lambertian type(任意入射角的反射光沿法线散射)如图3(b)所示。我们对两种散射模式和五个变量(Gaussian type 0°、Gaussian type 5°、Gaussian type 10°、Gaussian type 15°和Lambertian type)的底部反射率和接收器反射率进行了模拟计算。散射模型示意图如图3(b)所示。底部反射率和接收器反射率的可变区间分别为93%~99%和20%~40%;完成模拟计算后,计算模拟的结果矩阵输出和CMOS采集的图像进行验证,如图2(b)所示。计算式使用均方误差计算,如方程式(1):
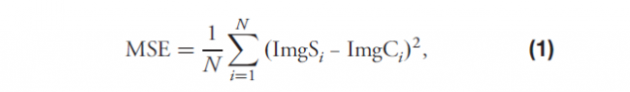
其中N是图像中的像素总数,i是像素索引,ImgS是仿真生成的图像,ImgC是通过CMOS传感器采集的图像。
在完成虚拟现实实验的MSE计算后,我们将MSE最小时的参数组合作为环境模型的基本参数。该方程表示为方程式(2):
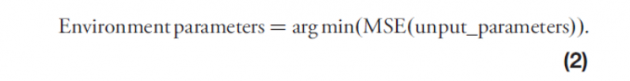
在完成环境参数值后,我们分别在PC2和PC3计算器中建立了微观尺度和宏观尺度的环境。PC2基于微尺度构建计算核心,其环境称为container2。container2中的计算内核为薄膜光学,主数据库为薄膜数据库,包含各种薄膜材料特性值,如折射率n、消光系数α等。另一方面,PC3构建了一个基于宏观尺度的计算核心,其环境称为container1。container1中的计算内核是蒙地卡罗光线追踪技术,主要数据库是材料数据库和双向散射分布函数(BSDF)数据库。container2 的计算生成了这个数据库,如图 3(c) 所示。当入射光进入薄膜表面时,会发生反射和折射。由于薄膜表面不是完全平坦的,无论是反射还是折射,都会产生散射的能量分布。BSDF数据库记录了由不同入射角的光线入射到薄膜堆上所产生的反射散射和折射散射的强度和角度分布。微观尺度和宏观尺度的光学问题,分别可以通过container1和container2的计算来处理。 完成PC2和PC3环境搭建后,两个计算引擎无法进行敏感传输。本文介绍了PC1 的环境控制代理程序,如图3(a)所示。该程序将强化学习的指令转移到PC2和PC3的工作调度;该方法可以同时将强化学习的动作分配给PC2和PC3进行并行处理和优化处理,或者直接将微观和宏观尺度的状态组织成统一的格式输出到强化学习进行运算。
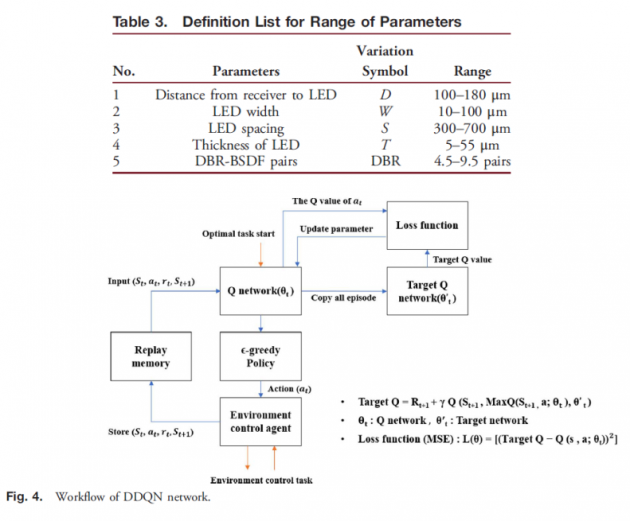
4.动作函数、状态函数、奖励函数的定义
从图2(a)可以看出,在强化学习中,环境和设计代理之间定义三个函式,动作、状态和奖励。参考图1(a)和1(b)的示意图中的设计参数,我们将动作函数定义为表 1。对于上下调整的五种变化,我们定义了a1-a10的动作函数。我们还针对五种变化状态定义了S1到S5的状态函数,如表2所示。最后,参考背光模块均匀度的定义,我们设置了三个不同的奖励函数为方程式(3)-(5):
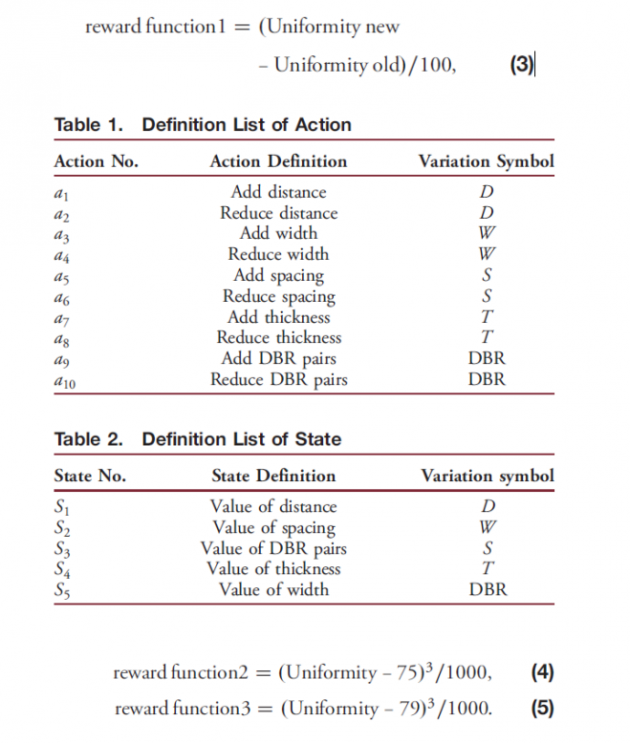
其中,方程式(3)采用浮动奖励计算系统,而方程式(4)和(5)采用固定均匀度比较法的计算系统。首先,我们需要在执行强化学习计算之前定义环境的边界值。 环境参数如表3。
5.Double deep Q-learning神经网络
如图2(a)所示,本文采用Double DQN(DDQN)网络作为优化算法。详细的计算过程如图 4 所示。动作 (at) 通过 ε-greedy策略计算给环境控制代理。在环境控制代理的控制和计算之后,回报第t和第 (t+1)状态St与St+1、动作和奖励值。每次迭代的状态、动作和奖励值都通过回放储存器记录下来。然后通过Q网络(θt)和目标Q网络(θ't)这两个神经网络,我们计算损失函数以确定新的参数更新。 目标 Q 和损失函数定义在方程式(6)和(7):
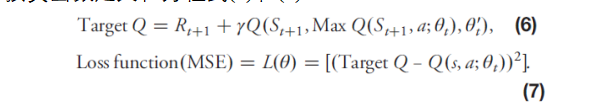
其中Rt+1是第(t+1)个状态的奖励值,γ是模型超参数,并且经过多次迭代,当损失函数值收敛时,可以得到一个最优的结果。
结果
1. 虚拟现实实验
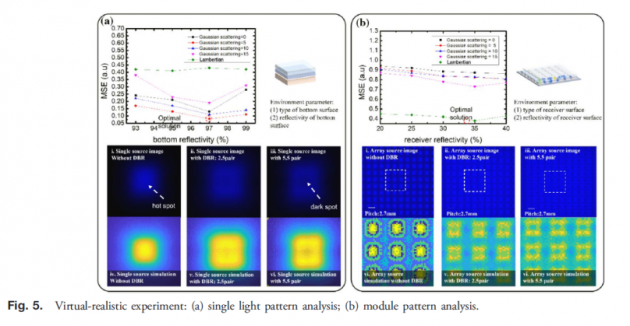
环境构建的参数设置往往是决定最终模型精度的重要因素。本文在环境搭建完成后开始进行虚拟现实实验。根据实际样品生产,我们使用氮化镓作为晶圆的外延结构,使用氮化铝/氮化镓作为DBR结构材料,其相关固定参数如表4所示。实验结果如图5所示。根据图5(a),我们给出了单片无DBR结构、2.5对DBR、5.5对DBR的实际拍摄结果,以及改变底部反射率后图像的MSE计算结果。结果,Gaussian type曲线均低于Lambertian type曲线,在反射率为97%时可以找到最小值。

从实验结果来看,我们可以选择MSE最低的参数:高斯散射为5,反射率97%作为底部反射率的环境参数,此外,图5(a)中的i、ii和iii面板分别显示了没有DBR、2.5对DBR和5.5对DBR的实际拍摄结果,而面板iv、v和vi是选择后的计算结果最佳底部反射率。发现没有DBR结构的芯片在光斑中心出现了亮度集中的热点现象,在模拟结果中也观察到了同样的现象,此外,DBR为5.5对光斑中间存在暗点现象,亮度低于周边,在模拟结果中也观察到了这一点。根据以上结果,这组底部反射率参数具有足够的可靠性。根据图5(b),我们展示了数组类型的实验结果,数组类型的实验结果主要用于计算最佳接收器反射率。在实际样品中,接收器是具有表面蚀刻图案的PMMA结构。这种结构的主要光学机制是反射、散射和折射。在本实验结果中,Lambertian type的MSE计算结果较低,而Lambertian type在反射率为35%时的MSE值最低,因此接收器反射率参数选择Lambertian type,即接收器反射率为35%。图 5(b)中的面板i、ii和iii分别显示了没有DBR、2.5对DBR和5.5对DBR的实际拍摄结果。可以发现使用DBR,芯片与芯片之间的暗带逐渐变亮。在面板 iv、v 和 vi 的模拟结果中也可以发现逐渐变亮的趋势。根据上述定性和定量分析结果,这组接收机反射率参数也具有足够的可靠性。
2. 强化学习的结果
构建环境后,我们使用 DDQN 网络进行强化学习,并设置了三种不同的奖励函式和强化学习中的参数优化边界,如表 3 和表 4。奖励函数1的设计定义为“严格递减”,这意味着要求每个损失必须低于前一个损失。此外,reward function2和reward function3被定义为与固定参考值相比的奖励函数。由于奖励函数 2 和 3 不需要遵循严格的增量规则,因此可以避免过拟合,收敛结果更稳定。实验结果显示在图6(a)、6(b)和6(c),表示使用奖励函数1、2和3的每次迭代的一致性。使用奖励函数1的迭代结果最初是不稳定的,结果的一致性为0经常出现。虽然经过250次迭代后才达到更稳定的运行优化,但该值仍然可以在稳定区域发现明显的衰减不稳定结果。 最好的结果出现在第 289 次迭代中。结果如图6(d)所示。根据平均Y=0 mm截止线的值,均匀度计算写为方程式(8):
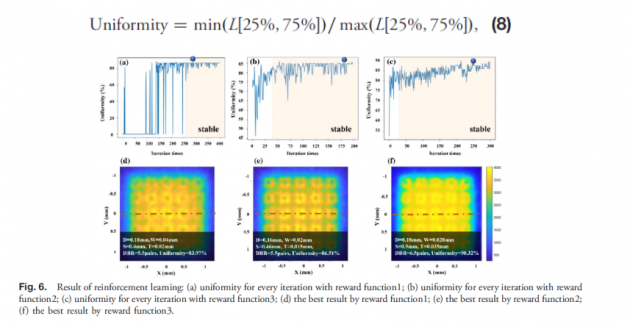
其中L是Y=0 mm时的截止线,L [25%,75%] 表示取 L 线第 25 到第 75 区间的值。
图6(d)显示了计算奖励函数 1 时最佳解的状态为Sb1 (D=0.18 mm,W=0.04 mm, S=0.4 mm, T=0.02 mm, DBR=5.5 pairs),均匀度为是83.97%。此外,在图6(b) 和 6(c) 使用奖励函数2和奖励函数3时,它们可以通过少量迭代达到稳定状态,并且不太容易出现计算崩溃。如图 6(b) 和 6(c) 所示,当迭代次数为183和249时,可以找到最佳解。最佳解决方案的结果如6(e)和6(f)所示。 状态为 Sb2 (D = 0.16 mm, W = 0.02 mm, S = 0.46 mm, T = 0.015 mm, DBR = 5.5 pairs)和 Sb3 (D = 0.18 mm,W = 0.028 mm, S = 0.5 mm,T = 0.035 mm,DBR = 6.5 pairs),均匀度分别为86.51%和90.32%。

3. 真实样本的结果
完成上述优化模型设计后,我们根据 Sb3 设计进行原型演示。 使用DBR结构可以降低整体颗粒度,如图7所示。
讨论
根据以上实验结果,采用本文提出的方法设计的设计代理可以有效优化光学设计,但更多的物理特性仍需总结。我们将重点关注以下几点并进行讨论。
(1) DBR 结构推断
(2) micro-LED 背光模块的能量损失机制
(3) micro-LED 背光模块的设计规则
(4) 强化学习的工作效率
1. DBR结构推断
首先,我们将状态 Sb3 (D = 0.18 mm,W = 0.028 mm,S = 0.5 mm,T = 0.035 mm,DBR = 6.5 pairs)最佳计算结果作为有DBR结构的实验组,并设置Sb3无DBR结构为对照组,S'b3 (D = 0.18 mm,W = 0.028 mm,S = 0.5 mm,T = 0.035 mm,DBR = 0 pairs)。比较结果如图8所示。图8(a)和8(b)分别是Sb3和S'b3的光学类别分布。很明显,没有DBR结构的S'b3有明显的热点分布,而有DBR结构的Sb3没有明显的热点分布。图8(c)显示了Sb3和S'b3在Y=0 mm处的能量分布结果,从这个结果可以计算出Sb3的照度为109,814 lux,均匀度90.32%,S'b3的照度为119,910 lux,均匀度为68.15%。DBR结构会将芯片发出的大量光反射到背板,造成一定程度的能量损失。此设计中的能量损失仅为8.5%。此外,反射光还改善了芯片之间的能量损失。空间的能量使原本分布在晶圆上方的光能被引导到晶圆之间的暗带。总体而言,DBR结构将均匀性提高了32%。
2. Micro-LED 背光模块的能量损失机制
从以上结果我们可以看出,DBR可以通过反射芯片的光来优化暗带的光能量。 在这个过程中,每次反射往往伴随着能量损失,如图9所示。DBR结构反射到背板的光产生的光损失是Micro-LED背光模块的主要能量损失机制,而另一个是接收器反射到背板的光造成的光损失,如图1所示。
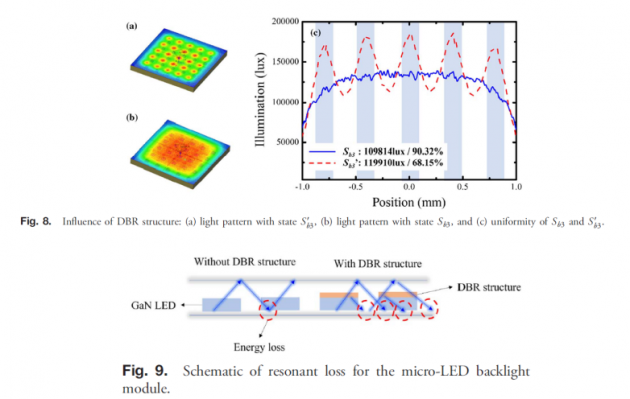
Micro-LED背光模块的结构由于考虑到optical event3和optical event4,从架构一开始就采用了高厚度高反射填料表面反射漆结构。虚拟现实实验结果表明,这种结构的反射率高达97%,使整个系统的光损耗降低到10%以内。
3. Micro-LED背光模块设计规则
表 5 提供了不同奖励函数设计下的优化结果。Sb1 (D=0.18 mm,W=0.04 mm, S=0.4 mm, T=0.02 mm, DBR=5.5 pairs),Sb2 (D = 0.16 mm, W = 0.02 mm, S = 0.46 mm, T = 0.015 mm, DBR = 5.5 pairs) 与Sb3 (D = 0.18 mm,W = 0.028 mm, S = 0.5 mm,T = 0.035 mm,DBR = 6.5 pairs)。进一步分析这三组状态的结果,除Sb2外,均得出光学距离D为0.18 mm的结论; 这个值是我们设定的优化参数范围内的最大值,这个结果与传统液晶背光模块的设计规律是一致的。另一方面,影响Sb1、Sb2、Sb3结果的主要因素是芯片之间的空间能量。如图8所示,将芯片中心的能量大角度转移的能力,有助于抑制芯片上的热点和芯片间的暗点现象。我们从 Sb1、Sb2 和 Sb3 中取出 W 和 T,并计算几何因子 f 为方程式(9)基于横向和前向发光表面积:

其中T是LED的厚度,W是LED的宽度。参数符号如图1所示。Sb1、Sb2 和 Sb3的f值分别为2、3和5。根据以往的研究,较大的f值可以提供较大的发光角度,增加芯片间距光学事件2的发生率。Sb3的DBR参数为6.5对,而Sb1和Sb2的DBR参数为5.5对。它具有较高的反射率,可以减少光学事件1的入射,减少光学事件1和增加光学事件2以实现显著的能量传递,从而使Sb3具有最佳的光学均匀性设计结果。
4. 强化学习的工作效率
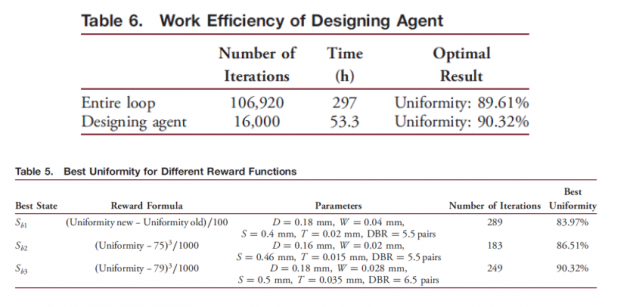
在这项研究中,通过强化学习和环境控制代理建立了一个高效的设计代理。为保证设计agent在参数限制区间内得到的解是最佳的,在表3中D、W、S、T、DBR定义的下限区间上增加step,进行全变量循环操作。参数D、W、S、T和DBR的步长分别为10、10、50、10和0.5。因此,我们得到D、W、S、T和DBR分别有18、10、9、6和11个变量值。总共有106,920种组合。总计算时间为297小时。获得的最佳结果是均匀度 89.61%。另一方面,采用了强化学习的设计。该代理共执行16,000次计算,耗时53.3 小时。获得的最佳结果是均匀性90.32%,如表6所示。因此,在优化求解时间中,设计代理只需要整个循环的17.9%。根据表6,虽然整个循环似乎描述了完整的解平面,但由于每个参数的步长都是固定值,所以整个循环所描绘的解平面是离散解的平面描绘。另一方面,它采用了具有深度学习解决方案特点的强化学习设计代理,即缩小搜索范围以找到最佳解决方案。因此,它可以提供更高效、更优的优化方案。
结论
传统的光学设计方法一般强调模型参数的准确性。有很多关于测量详细参数的研究; 然而,同时考虑极端尺度的影响可能具有挑战性。本研究引入的环境控制代理技术将微观尺度和宏观尺度模型高效地整合为一组优化模型,消除了不同计算尺度带来的所有计算障碍。强化学习模型还提供了一种针对Micro-LED背光模块的高效模型优化设计方法。与全循环模式相比,可以确定解平面上分辨率更高的最优位置;因此,设计代理的优化结果比整个循环的优化结果要好一些。此外,与多参数离散循环解相比,设计代理可以找到更准确的解,只需要整个循环时间的17.9%即可找到解。本研究采用新颖的多环境控制方法和强化学习框架,成功开发出具有DBR结构的Micro-LED背光模块作为背光均匀度优化组件,与没有DBR结构的Micro-LED背光模块相比,其均匀度提升了32%。
文章来源:鸿海研究院
作者:第一作者黄哲瑄台湾交大博士,中国台湾阳明交通大学教授郭浩中,通讯作者深圳大学微电子研究院材料学院研究员刘新科
原文链接:
